A unified framework bridging behavior-cloning pre-training and reinforcement-learning fine-tuning.
Our method
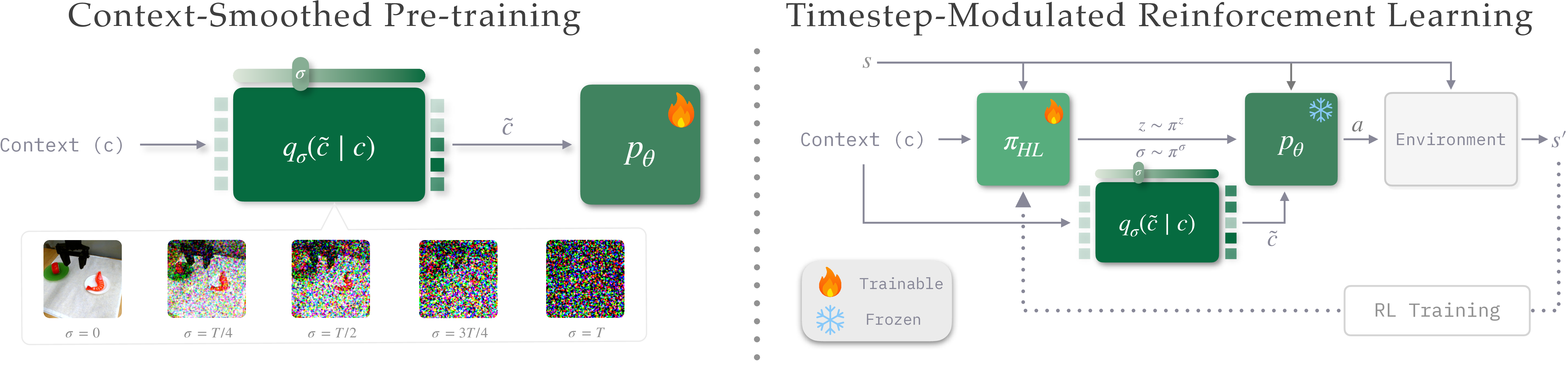
Context-Smoothed Pre-training (CSP) applies a diffusion-style forward-noising schedule to policy inputs, producing a continuous spectrum from precise imitation to broad coverage. Timestep-Modulated RL (TMRL) then trains a high-level policy πHL(z, σ | s) to select σ per action chunk.
Results
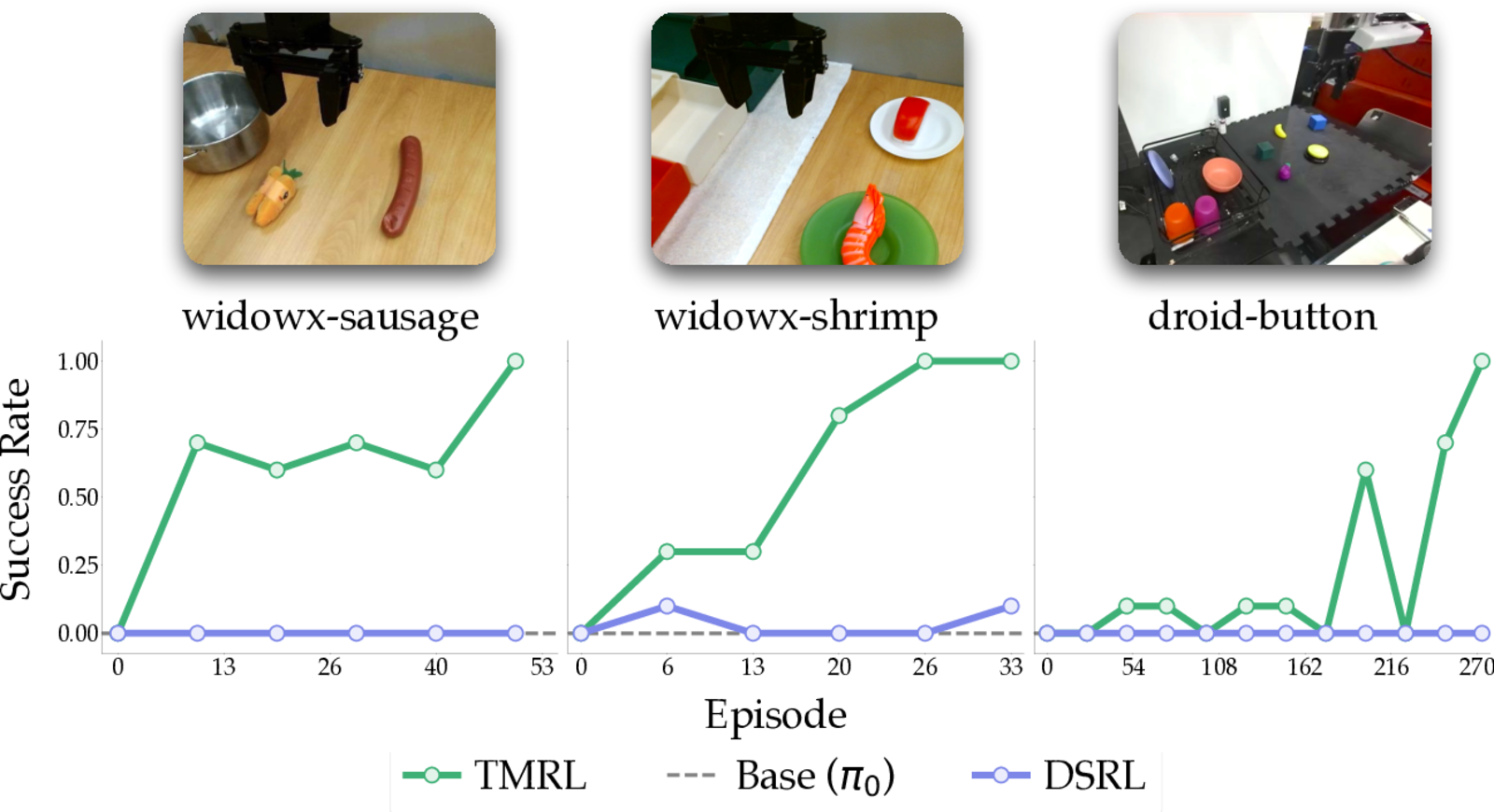
Real-world fine-tuning of π0 to near-perfect success on three robot tasks: under an hour on WidowX, under four on Franka. Outperforming state-of-the-art baselines in simulation.
Motivation
The need for action distribution interpolation.
Robots trained by imitation copy demonstrations narrowly — in sparsely covered contexts the conditional support collapses to near-zero probability on optimal actions, so online rollouts yield no reward signal and RL fine-tuning stalls. We propose to inject forward-diffusion noise into policy inputs at pre-training, smoothly interpolating between the conditional p(a | c) and marginal p(a) action distributions — broadening action coverage so RL can find solutions beyond the demonstrations.
On a 2D pointmaze from OGBench, we train two policies — one approximating p(a | c), the other p(a) — where c is the goal position. Both train on pointmaze-large and evaluate on the larger pointmaze-giant environment, with an unseen goal location (agent in yellow, goal in pink).
Watch the OOD goal: left,p(a | c) collapses and drifts away. Right,p(a) covers broadly enough to reach.
p(a | c) · BCp(a) · CSP, σ = T
The conditional collapses on optimal actions; the marginal covers them only with low likelihood. Thus motivating a policy that can interpolate between the two — and a mechanism to learn where on that interpolation to operate.
Method
Context smoothing & timestep modulation.
Fig. 1.Left — CSP (pre-training): one policy pθ trained across all σ by corrupting context c with qσ — precise imitation at σ = 0, broad coverage at σ = T. Right — TMRL (fine-tuning): the high-level policy πHL(z, σ | s) learns to modulate σ per action chunk to maximize reward.
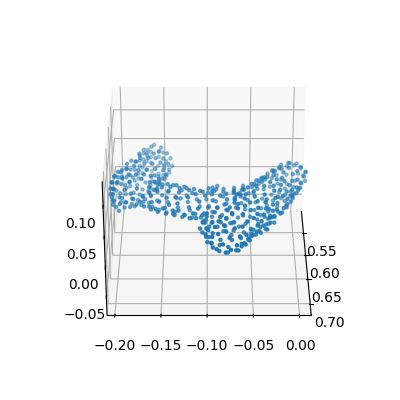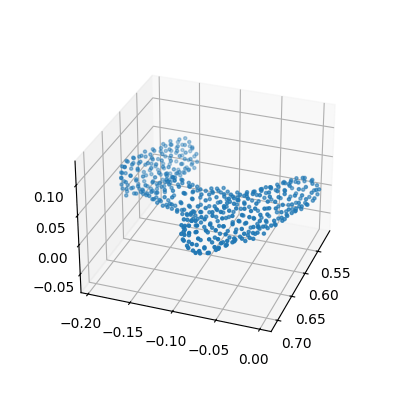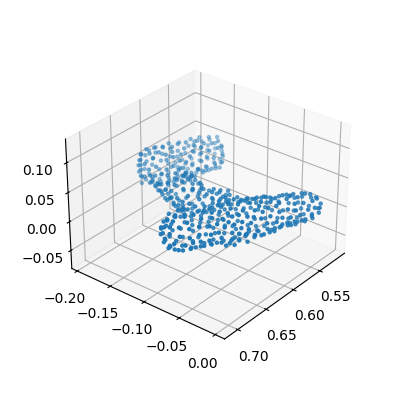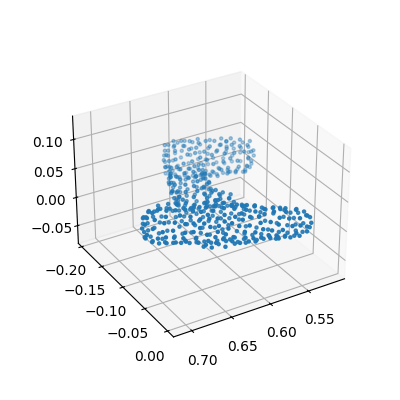
Diffusion noise on pointcloud contexts
On the dexterous-grasping suite, the context c is the object pointcloud. As σ rises, qσ progressively corrupts c: the pointcloud slowly loses its original structure, aliasing the out-of-distribution object with nearby in-distribution pointclouds seen during training. The policy can then borrow coherent grasps from related training contexts rather than failing on an unfamiliar shape.
1 · Reference rollout
noising c with qσ ↓
2 · Context-smoothed pointcloud
t = 0 · cleant = 0.001t = 0.01t = 0.1
Top:TMRL on a held-out drill (context c = pointcloud). Bottom:qσ removes structure as t rises — aliasing the OOD object back to in-distribution shapes the policy has seen during training.
σ Slider
The conditional ↔ marginal spectrum.
CSP trains one policy across all σ by corrupting the context c with qσ(c | c). The endpoints anchor the spectrum: σ = 0 recovers p(a | c), σ = T recovers p(a).
Drag σ below to see how the policy’s rollouts spread as the context input is more aggressively noised.
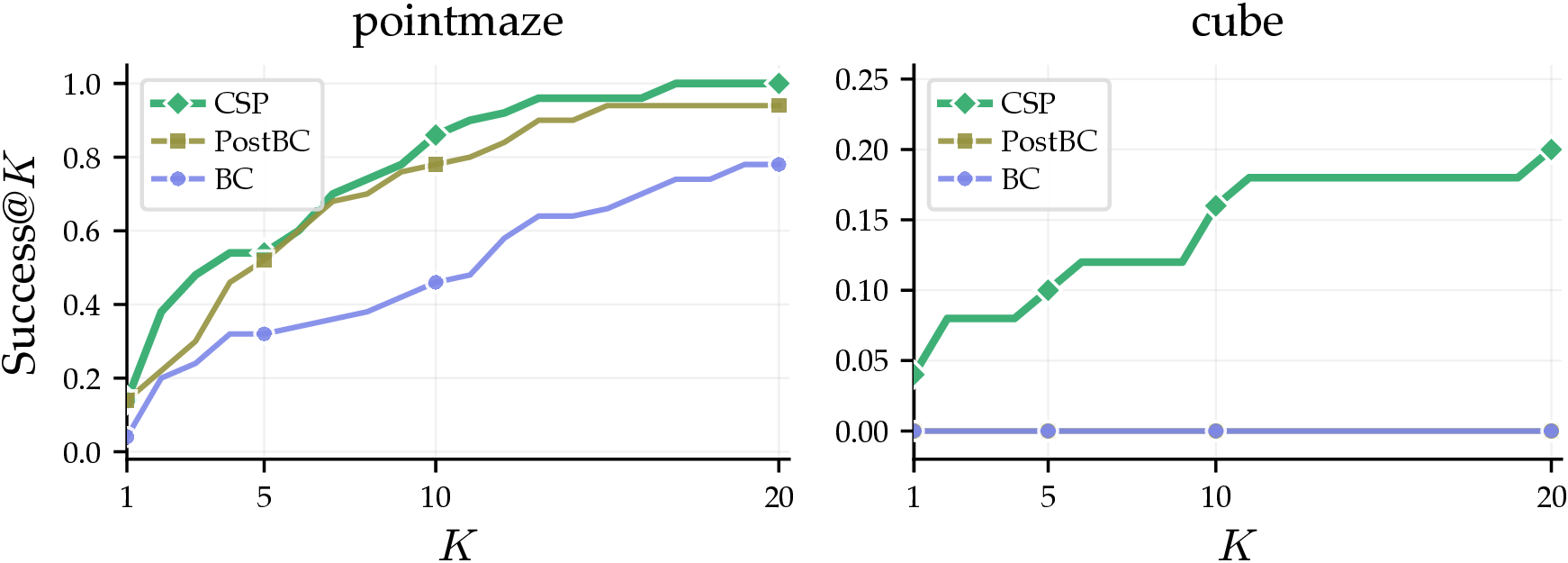
Success@K — the fraction of out-of-distribution states where at least one of K base-policy rollouts succeeds. On pointmaze-giant and cube-single, CSP exceeds PostBC and BC at every K, with the gap widest on cube-single where both baselines remain at zero.
CSP provides coverage before RL. BC and PostBC stay near zero on cube-single; CSP rises with K.
RL sample efficiency
We compare against several state-of-the-art baselines. TMRL outperforms or matches all baselines across four simulation tasks.
Simulation RL success rates. TMRL approaches 100% across all four tasks; only TMRL reaches non-trivial success on the long-horizon libero-90.
Real-World RL
Context-Smoothed π0 in the real world.
< 1 hr
DSRL never converges on either WidowX task. TMRL reaches near-perfect success in under an hour of real-robot fine-tuning on both (sausage-in-pot, shrimp-in-drawer).
CSP for VLAs. Noise the VLM embedding context with qσ to allow π0 to sample across the conditional → marginal spectrum.
We fine-tune a context-smoothed π0 on
BridgeData-v2 (WidowX 250) and
DROID (Franka).
Learning curves. Base π0 stalls — its action support is too narrow for any rollout to succeed. CSP widens that support; TMRL leverages it to reach near-perfect success on all three tasks.
Per-task rollouts
Base π0 versus context-smoothed π0, side by side. The learning curve below traces the full RL training run.
Base π0
Context-Smoothed π0(ours)
Real-world RL learning curve
Button Press
TMRL learns to be precise when it matters.
πHL treats the diffusion timestep t̃ as an adaptive coverage control, choosing it per action chunk. Below, the converged TMRL policy on WidowX shrimp-in-drawer learns to use t̃ low through the precision-critical pick (precise imitation) and higher during reaching and placing.
“pick up the shrimp and put it into the white drawer”
Action Chunk 1 / 10
t̃ = 0.01
BibTeX
@inproceedings{hong2026tmrl,
title = {TMRL: Diffusion Timestep-Modulated Pre-training Enables Exploration for Efficient Policy Fine-tuning},
author = {Hong, Matthew M. and Zhang, Jesse and Nagabandi, Anusha and Gupta, Abhishek},
booktitle = {Robotics: Science and Systems (RSS)},
year = {2026}
}